Zhao (Joey) Zhang (张 钊)
I'm currently working as a Senior Research Scientist at
![]() Canva
,
with a focus on Image Generation and Multimodal LLMs.
I completed my Master's degree at Nankai University,
where I was under the supervision of
Ming-Ming Cheng.
Please feel free to contact me at
(📮: zzhang🥳mail🔅nankai🔅edu🔅cn)
Canva
,
with a focus on Image Generation and Multimodal LLMs.
I completed my Master's degree at Nankai University,
where I was under the supervision of
Ming-Ming Cheng.
Please feel free to contact me at
(📮: zzhang🥳mail🔅nankai🔅edu🔅cn)
You can also find me in
![]() and
and
![]()
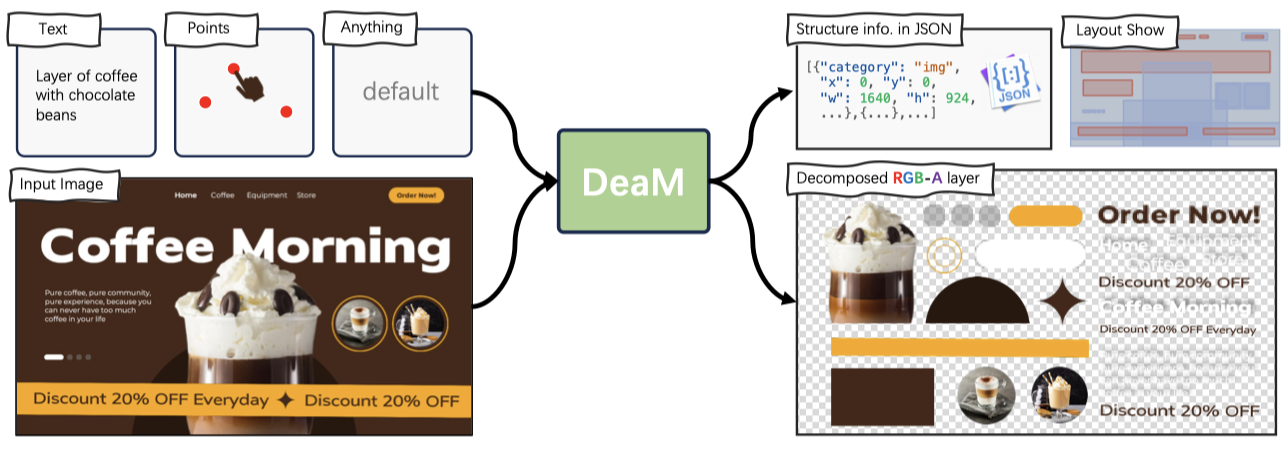
 , turning flat or AI-generated images into fully editable, multi-layer designs.
, turning flat or AI-generated images into fully editable, multi-layer designs.